Collection of data and data file extensions in Hamlet II
In the previous article, the interface of the Hamlet II software was discussed. This article presents the methods of collection of data and the type of data file extensions in Hamlet II software. The software has different file formats or extensions depending upon the type of analysis. Therefore, it is very important to know the use of every file format and the mode of collection of data.
Types of data file extensions in Hamlet II
Brier & Hopp (2015) provide the list of data file extensions in Hamlet II.
Data file extension |
Description |
| .voc | Vocabulary lists for use with Hamlet joint frequencies. |
| .mat | Matrix of co-occurrences of word pairs, from Hamlet Joint Frequencies, used as input to MINISSA, Cluster Analysis, or INDSCAL. It is also used to store arc-distances in the analysis of subject spaces, expressed as similarities. However, this must not be confused with Windows Office access (.mat) format files. |
| .xpr | Context profiles created by Hamlet joint frequencies and latent Dirichlet allocation for use with singular value decomposition (MDPREF) and correspondence analysis. |
| .svd | Results of singular value decomposition (MDPREF). |
| .xpc | Results of correspondence analysis. |
| .ham | Output listing from Hamlet joint frequencies. |
| .txt | Listing of word clusters identified by cluster analysis. |
| .min | MINISSA output listing, accessed by SELECT to generate input to PINDIS. |
| .stp | ‘Stoplist’ file used in association with WORDLIST, VOCEDIT and LDA. |
| .ins | INDSCAL input file. |
| .ind | INDSCAL output listing. |
| .inp | PINDIS input file. |
| .pin | PINDIS output listing. |
| .bmp, .jpg | Graphic files to store results displayed by MINISSA, PINDIS, singular value decomposition (MDPREF), correspondence analysis, INDSCAL and PROFILE. |
| .lst | Wordlist file, generated by Wordlist or Compare. |
| .kwc | Key-Word-In-Context listing. |
| .win, .cfg | Language convention files. |
Collection of data
Data is presented in text form when collected via questionnaires formed for interviews or qualitative studies. Therefore, it is collected in either word document .doc or converted to .txt format. Hamlet II accepts only .txt files.
In social researches, qualitative studies comprise of interviews or focus group interviews. The three most common qualitative methods are participant observation, in-depth interviews, and focus groups. Each method is particularly suited for obtaining a specific type of data.
Computer-generated transcription
Computer-generated transcription is derived from audio player or video files from interviews and other similar data collection techniques. There are softwares that allow conversion or transcription of data from voice or audio files to texts, of which Dragon and NVivo are popular. Google Docs is another option with a speech to text option. However, it is important to know that no software gives 100% perfect transcription. Hence cross-checking for left out text is important for appropriate analysis.
Transcript for Hamlet II
The following points are important for analysis in Hamlet II software.
- Firstly it must be in .txt format.
- Secondly, questions from the interviews must avoid reducing repetition of words.
- Words like ‘interviewer’, ‘respondent’ and etc. must be ignored because they add no value to your analysis.
- Avoid numerical as well as special characters.
- The transcript must follow a particular language. For instance, if a researcher is using English, the complete transcript must comprise of English language only.
- Lastly, use automated transcript but with final manual transcript proofread.
Difference between good and bad transcript
The two images present the difference between good and bad transcripts for usage in Hamlet II.
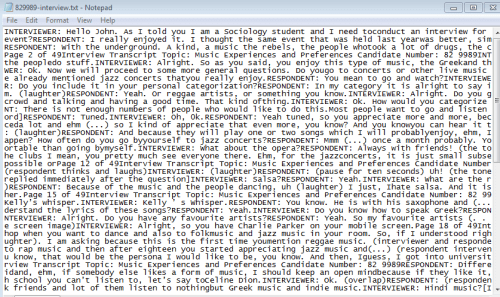

As the above image shows, the good example of transcript for Hamlet II shows the removal of numerical and special characters. The image also presents removal of ‘respondent’ or ‘interviewer’ type of words. Moreover, the output ignored the interview questions, while using a singular language throughout.
Text analysis and interpretation
This article presents the importance of qualitative data collection for Hamlet II. Furthermore, in this module, the next article focuses on textual analyses and their interpretations.
References
- Brier, A., & Hopp, B. (2015). HAMLET II 3.0: Software for computer assisted text analysis. Southampton/Cologne. Retrieved from http://apb.newmdsx.com/hamlet2.html.
I am a management graduate with specialisation in Marketing and Finance. I have over 12 years' experience in research and analysis. This includes fundamental and applied research in the domains of management and social sciences. I am well versed with academic research principles. Over the years i have developed a mastery in different types of data analysis on different applications like SPSS, Amos, and NVIVO. My expertise lies in inferring the findings and creating actionable strategies based on them.
Over the past decade I have also built a profile as a researcher on Project Guru's Knowledge Tank division. I have penned over 200 articles that have earned me 400+ citations so far. My Google Scholar profile can be accessed here.
I now consult university faculty through Faculty Development Programs (FDPs) on the latest developments in the field of research. I also guide individual researchers on how they can commercialise their inventions or research findings. Other developments im actively involved in at Project Guru include strengthening the "Publish" division as a bridge between industry and academia by bringing together experienced research persons, learners, and practitioners to collaboratively work on a common goal.
Discuss